2-1.リストの処理¶
加算は+、乗算は*。添字はtext[2]、スライスはtext[1:5]等のようにする(1章)。 ソートはsortメソッドを使用する(4章)。
2-2.コーパスのデータ¶
- コーパスのデータを取得し、長さを調べる。 ::
>>> len(nltk.corpus.gutenberg.words('austen-persuasion.txt')) 98171 >>> len(set(nltk.corpus.gutenberg.words('austen-persuasion.txt'))) 6132
2-3. ブラウンコーパスとウェブテキストコーパス¶
それぞれのデータを見比べる(コードは省略)。
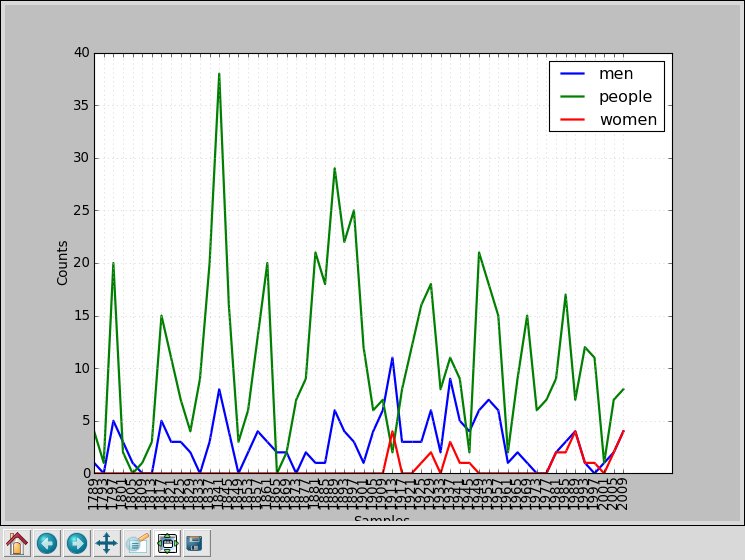
2-4.一般教書演説¶
一般教書演説に見られる、men, women, people の割合。
>>> cfd = nltk.ConditionalFreqDist(
... (target, fileid[:4])
... for fileid in inaugural.fileids()
... for w in inaugural.words(fileid)
... for target in ['men', 'women', 'people']
... if w.lower().startswith(target))
>>> cfd.plot()