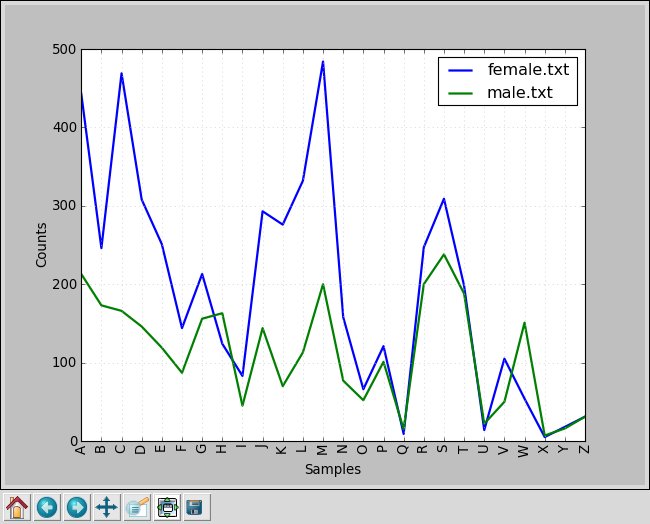
2-8.名前の頭文字と男女¶
頭文字によって、男女の差が結構ある。
>>> from nltk.corpus import names
>>> male_names = names.words('male.txt')
>>> female_names = names.words('female.txt')
>>> cfd = nltk.ConditionalFreqDist(
... (fileid, name[0])
... for fileid in names.fileids()
... for name in names.words(fileid))
>>> cfd.plot()
2-9. テキスト間での語彙の違い¶
concordance 等を使って地道に調べるしかないかも?
2-10.頻度上位語¶
頻度の高い順に出現頻度を足していく。合計が1/3以上になるまで足していき、そのときの単語数を表示する。
>>> def onethird(text):
... fdist = FreqDist(text)
... word_freq = 0
... word_count = 0
... while word_freq * 3 < 1:
... word_freq += fdist.freq(fdist.keys()[word_count])
... word_count += 1
... return word_count
...
>>> onethird(text1)
17
>>> onethird(text2)
18
>>> onethird(text3)
10
>>> onethird(text4)
13
>>> onethird(text5)
32
>>> onethird(text6)
12
>>> onethird(text7)
23